Intro to XHTML series
3. How is XHTML different from HTML?
If you watched the previous tutorial, you'll know that XHTML is the successor to and generally preferred over HTML. What you don't know is why.
As far as computer languages go, HTML has a very loose syntax. It leaves lots of room for coders to write sloppy code. This makes it potentially harder for humans as well as computers to read.
XHTML takes the potential for human and computer errors out of HTML by making its syntax stricter and more consistent. It's much easier for a web browser to consistently process and display a properly coded web page than one that's been coded improperly.
It is true that HTML can be coded consistently, but then it looks almost identical to XHTML. So, the main advantage of XHTML over HTML is that it doesn't just allow consistency, it requires it.
The most important reason that you should learn XHTML rather than HTML is that consistent languages are easier to learn.
Let's look at an example. We'll show you an HTML document that is very poorly coded, but still valid HTML.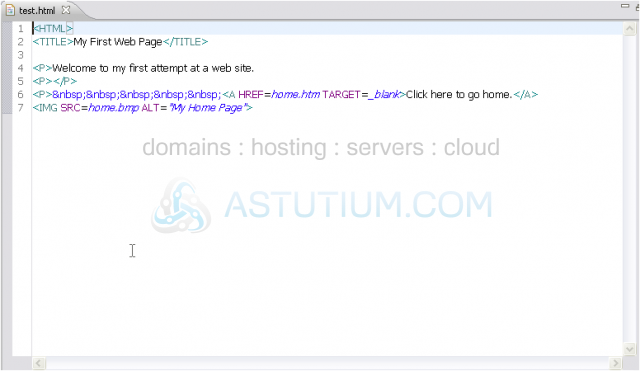
Even thinking about maintaining a full website that's been coded this poorly would make most web developers cringe.
Let's turn this mess into properly coded HTML that could easily be converted to XHTML.
1) Start by changing all the tags to lowercase. XHTML requires this.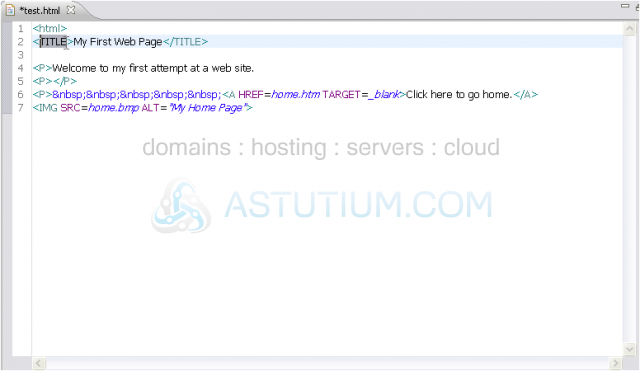
2) Do the same for any attributes. This is also a requirement of XHTML.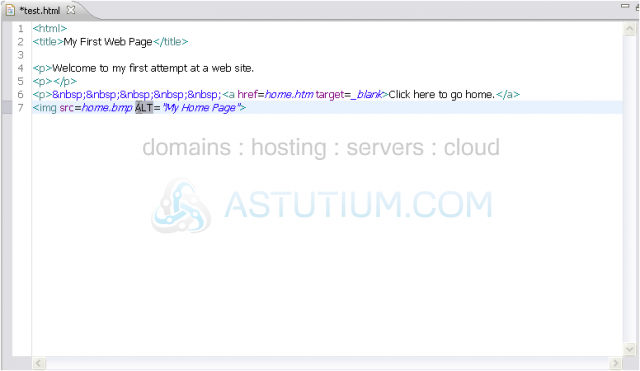
This document is also malformed. Two of the required elements of an XHTML page are not present - head and body. You'll hear more about those later.
3) Let's add them both now, starting with head.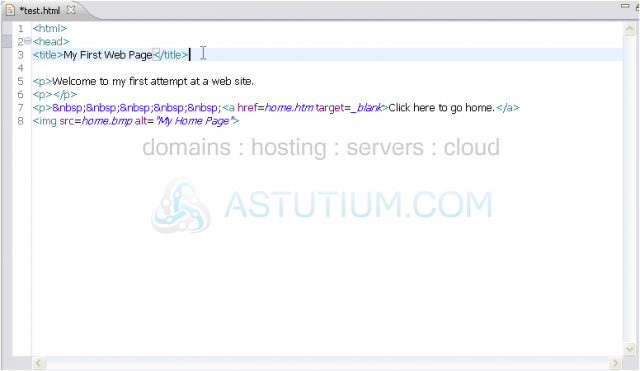
4) To help show that <title> is inside <head>, let's indent this line.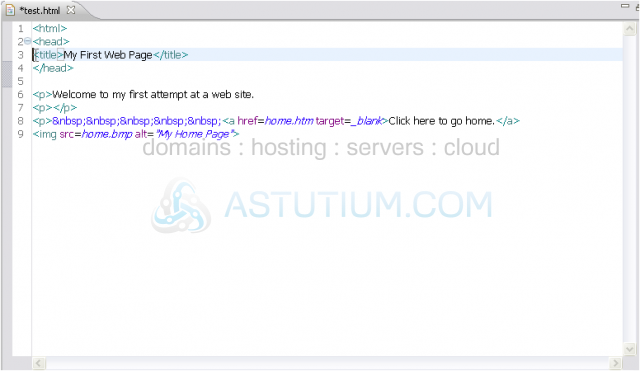
5) Now to add body.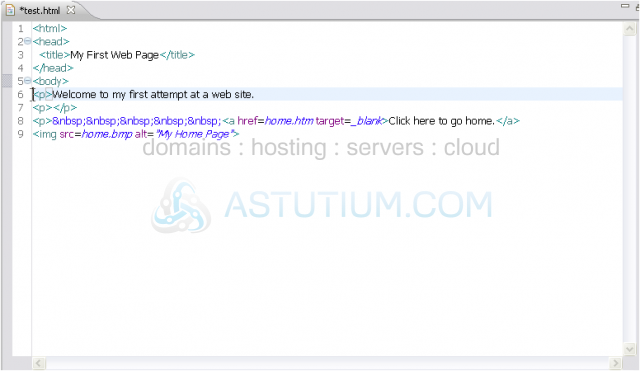
6) And indent again.
7) These paragraph tags need to be closed.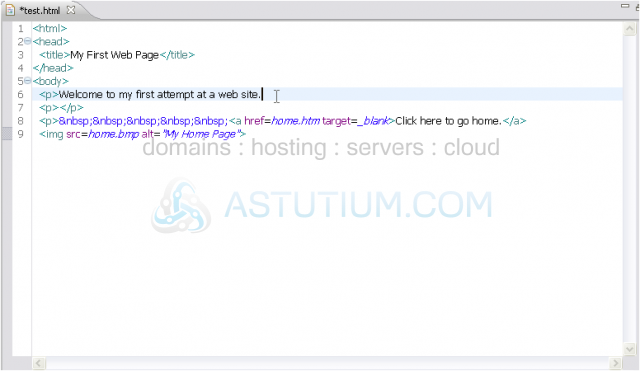
8) Now, we need to close the body and html tags.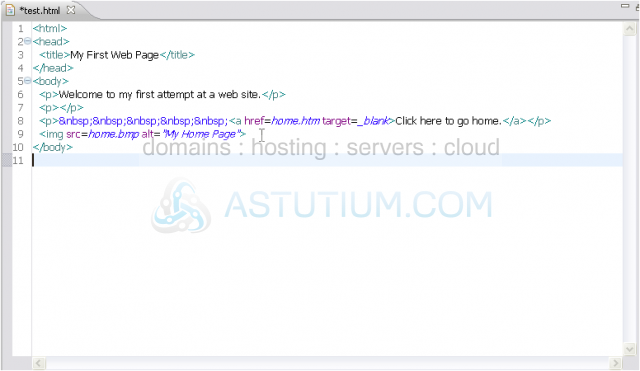
9) An image tag can never contain text or another tag, so it doesn't need a closing tag. For cases like these, a slash before the last angle bracket is necessary. You should always put a space before the slash.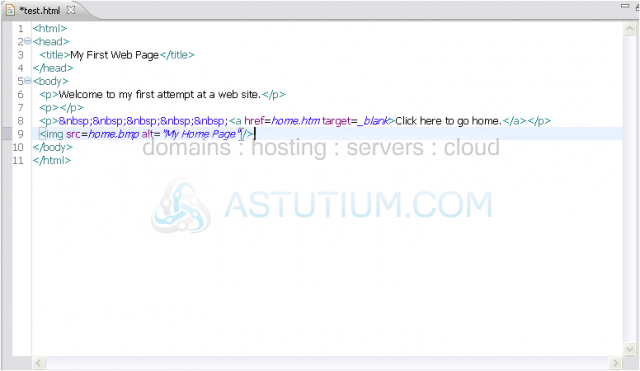
10) The final problem with this document is that most of the attribute values are not quoted. Let's fix that.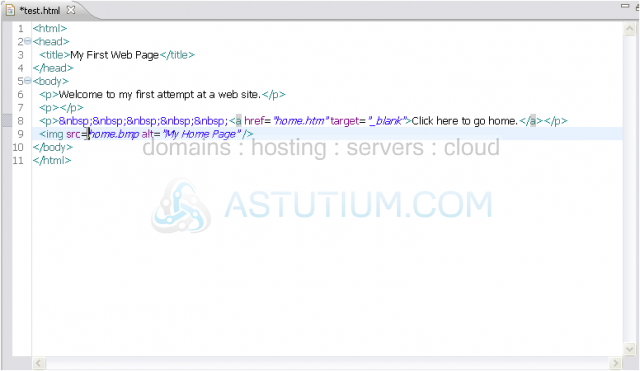
That's it! All of the problems with this HTML document have been fixed. This isn't quite XHTML, but very close. There are a few more requirements that we haven't fulfilled, but we'll get to those in later tutorials.
Let's compare the corrected version to the original, just at a glance.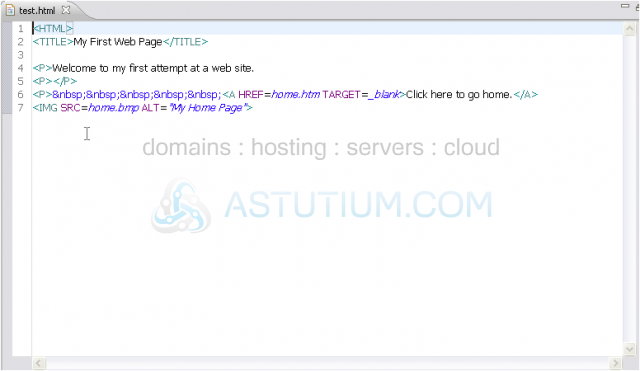
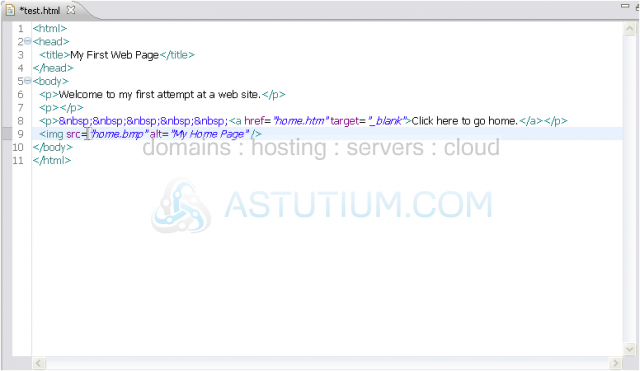
You may think our new version is more complicated and that the way it was before wasn't too bad. Multiply this code by 50 lines and then across 30 pages, and you'll quickly change your mind.
This is the end of the tutorial. You now know the key differences between HTML and XHTML, and how to fix a poorly coded HTML document.